что это за технология в HTML и JS
DOM — это объектная модель документа, которую браузер создает в памяти компьютера на основании HTML-кода, полученного им от сервера. Иными словами, это представление HTML-документа в виде дерева тегов.
Такое дерево нужно для правильного отображения сайта и внесения изменений на страницах с помощью JavaScript. JavaScript — это «живой» язык, он может изменять страницу в реальном времени уже после того, как она «пришла» с сервера в браузер. Этим JavaScript принципиально отличается от PHP, который компилирует страницу и только потом посылает в браузер уже готовый HTML-код.
Схема отображения страницы в браузере. Источник
Для чтения и изменения DOM браузеры предоставляют DOM API (программный интерфейс). DOM API — это набор различных объектов, которые разработчик использует для чтения и изменения DOM с помощью JavaScript.
Из чего состоит HTML-код страницы
Страница на HTML состоит из тегов, вложенных в друг друга. Самый общий тег — это HTML. В него вкладываются два дочерних тега head и body.
В него вкладываются два дочерних тега head и body.
Тег head используется для подключения информации, которая не будет отображаться непосредственно на странице, но будет использоваться для подключения важных файлов. Тут бывает, например, подключение одного или нескольких CSS-файлов, подключенные шрифты, название сайта, язык, кодировка, скрипты, которые должны выполняться в первую очередь, иконка сайта или базовый фон.
В body находится значимое содержимое. Обычно в body выделяют три части: шапка сайта, основное содержимое и подвал. В шапке обычно содержится верхнее меню сайта, за это отвечает тег header. Для содержимого нет определенного тега, но обычно используется section. Для подвала используется footer, там обычно содержатся контактная информация, ссылки на ключевые страницы сайта и копирайт. Теги header и footer должны быть единственными на странице, а section может бесконечно повторяться.
Как строится DOM-дерево
Для описания структуры DOM потребуются термины: корневой, родительские и дочерние элементы. Корневой элемент находится в основании всей структуры и не имеет родительского элемента. Дочерние элементы не просто находятся внутри родительских, но и наследуют различные свойства от них. На картинке ниже изображено DOM-дерево.
DOM-дерево
Корневой элемент здесь html — без него страница не будет скомпилирована. Он не имеет родительского (вышестоящего) элемента, но имеет два наследника или дочерних элемента — head и body.
По отношению друг к другу элементы head и body являются сиблингами (братьями и сестрами). В каждый из них можно вложить еще много дочерних элементов. Например, в head обычно находятся link, meta, script или title.
Все эти теги не являются уникальными, и в одном документе может быть по несколько экземпляров каждого из них.
В body могут находиться разнообразные элементы. Например, в родительском body — дочерний элемент header, в элементе header — дочерний элемент section, в родительском section — дочерний div, в div — элемент h4, и наконец, в h4 — элемент span. В этом случае span не имеет дочерних элементов, но их можно добавить в любой момент.
В этом случае span не имеет дочерних элементов, но их можно добавить в любой момент.
Можно описать это так:
Графическое представление элементов HTML-страницы
А если бы система была бы более разветвленная и с большим количеством вложений — так:
Графическое представление элементов HTML-страницы
На схеме изображено довольно большое DOM-дерево, и его сложно воспринимать из-за его размера. Для удобства часто используется система многоуровневых списков. Например, предыдущее дерево можно преобразовать в такой список:
Представление элементов HTML-страницы в виде списка
Если преобразовать дерево на предыдущем рисунке в код, то получится так:<HTML> <head> <link> <link> <link> <meta> <meta> <title></title> </head> <body> <header> <div> <h4></h4> </div> <div> <h5> <span></span> </h5> </div> <div> <p></p> </div> <div> <img> </div> </header> <section> <div> <h4></h4> <p> <span></span> </p> </div> <div> <p> <span></span> </p> <img> <p></p> <div> <img> <iframe></iframe> </div> </div> </section> <footer> <div> <img> <p></p> </div> <div> <h6></h6> </div> </footer> </body> </HTML>
Как видно из кода, некоторые теги должны закрываться, а некоторые — нет.
Эту схему важно понимать, чтобы разобраться с темой наследования свойств. Элементы могут наследовать не все, но многие свойства своих родителей — например, цвет, шрифт, видимость и т.д.
Таким образом, чтобы задать стиль шрифта на всей странице, потребуется не прописывать цвет для каждого элемента, а задать его только для body. А чтобы изменить наследуемое свойство у дочернего элемента, нужно прописать только ему новые свойства. Наследование удобно для создания единообразной страницы.
Зачем нужно знать, как строится DOM-дерево?
Большинство действий при работе с DOM сводится к поиску нужных элементов. Не понимая, как строится DOM-дерево, и не зная, каковы связи между узлами, найти нужный элемент будет сложно.
Как просмотреть DOM-дерево?
В любом браузере есть инструменты, с помощью которых можно отобразить DOM-дерево. Если выбрать какой-либо объект в структуре, он будет подсвечен на странице. При этом для него будут выведены свойства CSS, которые работают сейчас, и те, которые не задействованы.
Чтобы посмотреть DOM в браузере, нужно зайти в инструменты разработчика. В большинстве браузеров для этого надо нажать на F12 — тогда откроется дополнительная панель с вкладками и зонами.
Просмотр DOM-дерева в браузере
На изображении выше во вкладке Elements представлена структура DOM в виде многоуровневого вложенного списка. Каждый элемент можно открыть и посмотреть, что у него внутри, его расположение на странице и размеры этого элемента со всеми отступами.
Также там находятся другие инструменты — например консоль, где выводится информация об ошибках и куда можно ввести необходимые данные, например для отладки (исправления ошибок в коде).
Панель ресурсов отображает подключенные ресурсы — это шрифты, изображения, JavaScript- и CSS-файлы.
Что такое DOM и зачем он нужен?
В этой статье мы изучим: как создаётся веб-страница в браузере, что такое DOM и зачем он нужен, как строится DOM-дерево, а также какие бывают типы узлов и отношения между ними.
Как создаётся веб-страница?
Браузер, перед тем как показать вам запрашиваемую страницу, выполняет большое количество различных действий. Самое важное здесь понять, что браузер не работает с HTML-страницей напрямую как с текстом, а строит для этого DOM.
Самое важное здесь понять, что браузер не работает с HTML-страницей напрямую как с текстом, а строит для этого DOM.
DOM – это объектная модель документа (Document Object Model). Представляет она собой древовидную структуру страницы, состоящую из узлов. Каждый узел в ней – это объект, который может иметь определённые свойства и методы. Иными словами, можно сказать, что DOM – это набор иерархически связанных между собой объектов.
Зачем браузер строит DOM? В основном это связано с тем, что прочитанный HTML-код ему нужно как-то представить в памяти и было решено, что оптимально это будет сделать в виде древовидной структуры. После того как браузер построил DOM, он его использует в дальнейших процессах, конечной целью которых является построения отображения этой страницы на экране.
Процесс перевода HTML-кода страницы в DOM выполняет парсер. При этом он это делает даже если HTML-код содержит ошибки, но так как он в данном случае это «понимает».
При этом DOM не является статической структурой. Её можно изменять с помощью JavaScript и тут же видеть эти изменения на экране. Для этого браузер нам предоставляет API. То есть благодаря DOM, мы можем с помощью JavaScript изменять содержимое страницы на лету. Таким образом, JavaScript – это ключевая технология для создания динамических веб-сайтов и веб-приложений. Без неё, каким-то других способом это сделать невозможно.
Её можно изменять с помощью JavaScript и тут же видеть эти изменения на экране. Для этого браузер нам предоставляет API. То есть благодаря DOM, мы можем с помощью JavaScript изменять содержимое страницы на лету. Таким образом, JavaScript – это ключевая технология для создания динамических веб-сайтов и веб-приложений. Без неё, каким-то других способом это сделать невозможно.
Перед тем как перейти к изучению DOM, рассмотрим сначала все основные этапы работ, которые браузер выполняет для преобразования исходного кода HTML-документа в отображение стилизованной и интерактивной картинки на экране. Кстати, этот процесс называется Critical Rendering Path (CRP).
Шаги CRP:
Хотя этот процесс состоит из большого количества шагов, их грубо можно представить в виде двух:
- Анализирует HTML-документ, чтобы определить то, что в конечном итоге нужно отобразить на странице;
- Выполняет отрисовку того что нужно отобразить.
Результатом первого этапа является формирование дерева рендеринга (render tree). Данное дерево содержит видимые элементы и текст, которые нужно отобразить на странице, и также связанные с ними стили. Это дерево дублирует структуру DOM, но включает как мы отметили выше только видимые элементы. В render tree каждый элемент содержит соответствующий ему объект DOM и рассчитанные для него стили. Таким образом, render tree описывает визуальное представление DOM.
Данное дерево содержит видимые элементы и текст, которые нужно отобразить на странице, и также связанные с ними стили. Это дерево дублирует структуру DOM, но включает как мы отметили выше только видимые элементы. В render tree каждый элемент содержит соответствующий ему объект DOM и рассчитанные для него стили. Таким образом, render tree описывает визуальное представление DOM.
Чтобы построить дерево рендеринга, браузеру нужны две вещи:
- DOM, который он формирует из полученного HTML-кода;
- CSSOM (CSS Object Model), который он строит из загруженных и распознанных стилей.
На втором этапе браузер выполняет отрисовку render tree. Для этого он:
- рассчитывает положение и размеры каждого элемента в render tree, этот шаг называется Layout;
- выполняет рисование, этот шаг называется Paint.
После Paint все нарисованные элементы находятся на одном слое. Для повышения производительности страницы браузер выполняет ещё один шаг, который называется Composite. В нем он группирует элементы по композиционным слоям. Именно благодаря этому этапу мы можем создать на странице плавную анимацию элементов при использовании таких свойств как
В нем он группирует элементы по композиционным слоям. Именно благодаря этому этапу мы можем создать на странице плавную анимацию элементов при использовании таких свойств как transform, opacity. Так как изменение этих свойств вызовет только одну задачу Composite.
Для работы со слоями в Chrome есть отличный инструмент Layers.
Например, изменения свойства color вызовет сначала задачу Paint, а затем вероятнее всего последует Composite всех затронутых элементов.
Изменение width вызовет следующие задачи: Layout -> Paint -> Composite.
Layout и Paint – это ресурсоемкие процессы, поэтому для хорошей отзывчивости вашей страницы или веб-приложения, необходимо свести к минимуму операции которые их вызывают.
Список свойств, изменение которых вызывают Paint:
color;background;visibility;border-styleи другие.

Список свойств, изменение которых вызывает Layout:
widthиheight;paddingиmargin;display;border;top,left,rightиbottom;position;font-sizeи другие.
Кроме этого, Layout срабатывает не только при изменении CSS-свойств, но также, например когда мы хотим получить смещение элемента (el.offsetLeft, el.offsetTop и так далее) или его положение (el.clientLeft, el.clientTop и так далее), а также во многих других случаях. Более подробно ознакомиться с этими операциями можно здесь.
Чтобы понимать какую стоимость имеет то или иное свойство, можно установить расширение css-triggers для редактора кода VS Code:
Что же такое DOM?
DOM – это объектное представление исходного HTML-кода документа. Процесс формирования DOM происходит так: браузер получает HTML-код, парсит его и строит DOM.
Процесс формирования DOM происходит так: браузер получает HTML-код, парсит его и строит DOM.
Затем, как мы уже отмечали выше браузер использует DOM (а не исходный HTML) для строительства дерева рендеринга, потом выполняет layout и так далее.
Почему не использовать в этом случае просто HTML? Потому что HTML – это текст, и с ним невозможно работать так как есть. Для этого нужно его разобрать и создать на его основе объект, что и делает браузер. И этим объектом является DOM.
Итак, DOM – это объектная модель документа, которую браузер создаёт в памяти компьютера на основании HTML-кода.
По-простому, HTML-код – это текст страницы, а DOM – это объект, созданный браузером при парсинге этого текста.
Но, браузер использует DOM не только для выполнения процесса CRP, но также предоставляет нам программный доступ к нему. Следовательно, с помощью JavaScript мы можем изменять DOM.
DOM – это технология не только для браузеров и JavaScript. Существуют и другие инструменты, позволяющие работать с DOM. Например, работа с DOM может осуществляться серверными скриптами, после загрузки и парсинга ими HTML-страницы. Но это немного другая тема и мы не будем рассматривать её здесь.
Например, работа с DOM может осуществляться серверными скриптами, после загрузки и парсинга ими HTML-страницы. Но это немного другая тема и мы не будем рассматривать её здесь.
Все объекты и методы, которые предоставляет браузер описаны в спецификации HTML DOM API, поддерживаемой W3C. С помощью них мы можем читать и изменять документ в памяти браузера.
Например, с помощью JavaScript мы можем:
- добавлять, изменять и удалять любые HTML-элементы на странице, в том числе их атрибуты и стили;
- получать доступ к данным формы и управлять ими;
- реагировать на все существующие HTML-события на странице и создавать новые;
- рисовать графику на HTML-элементе
<canvas>и многое другое.
При изменении DOM браузер проходит по шагам CRP и почти мгновенно обновляет изображение страницы. В результате у нас всегда отрисовка страницы соответствует DOM.
Благодаря тому, что JavaScript позволяет изменять DOM, мы можем создавать динамические и интерактивные веб-приложения и сайты. С помощью JavaScript мы можем менять всё что есть на странице. Сейчас в вебе практически нет сайтов, в которых не используется работа с DOM.
С помощью JavaScript мы можем менять всё что есть на странице. Сейчас в вебе практически нет сайтов, в которых не используется работа с DOM.
В браузере Chrome исходный HTML-код страницы, можно посмотреть во вкладке «Source» на панели «Инструменты веб-разработчика»:
На вкладке Elements мы видим что-то очень похожее на DOM:
Однако DevTools включает сюда дополнительную информацию, которой нет в DOM. Отличным примером этого являются псевдоэлементы в CSS. Псевдоэлементы, созданные с помощью селекторов ::before и ::after, являются частью CSSOM и дерева рендеринга, и технически не являются частью DOM. Мы с ними не может взаимодействовать посредством JavaScript.
По факту DOM создается только из исходного HTML-документа и не включает псевдоэлементы. Но в инспекторе элементов DevTools они имеются.
Как строится DOM?
Перед тем, как перейти к DOM, сначала вспомним, что собой представляет исходный HTML-код документа. В качестве примера рассмотрим следующий:
<!doctype html>
<html lang="ru">
<head>
<title>Моя страница</title>
</head>
<body>
<h2>Мобильные ОС</h2>
<ul>
<li>Android</li>
<li>iOS</li>
</ul>
</body>
</html>Как вы уже знаете, HTML-документ – это обычный текстовый документ. Его код состоит из тегов, атрибутов, текста, комментариев и так далее. Очень важной сущностью в нём является HTML-элемент. На них всё строится. HTML-элемент в большинстве случаев состоит из открывающего и закрывающего тегов, между которыми располагается его содержимое. Например, HTML-элемент
Его код состоит из тегов, атрибутов, текста, комментариев и так далее. Очень важной сущностью в нём является HTML-элемент. На них всё строится. HTML-элемент в большинстве случаев состоит из открывающего и закрывающего тегов, между которыми располагается его содержимое. Например, HTML-элемент h2 имеет открывающий тег <h2>, закрывающий </h2> и содержимое «Моя страница». Кроме этого, тег может содержать дополнительную информацию посредством атрибутов. В этом коде атрибут имеется только у HTML-элемента <html>.
Также очень важно понимать, что в HTML-коде одни элементы вкладываются в другие. Например, <h2> вложен в <body>, а <body> в <html>. Это очень важная концепция, которая нам и позволяет нам создавать определённую разметку в HTML.
Теперь рассмотрим, как браузер на основании HTML-кода строит DOM. Объектная структура DOM представляет собой дерево узлов (узел на английском называется node). При этом DOM-узлы образуются из всего, что есть в HTML: тегов, текстового контента, комментариев и т.д.
При этом DOM-узлы образуются из всего, что есть в HTML: тегов, текстового контента, комментариев и т.д.
Корневым узлом DOM-дерева является объект document, он представляет сам этот документ. Далее в нём расположен узел <html>. Получить этот элемент в коде можно так:
const elHTML = document.documentElement;
В <html> находятся 2 узла-элемента: <head> и <body>. Получить их в коде можно так:
const elHead = document.head; const elBody = document.body;
В <head> находится DOM-узел <title>:
// получим <title> и присвоим его переменной elTitle const elTitle = document.title;
В <title> находится текстовый узел. Теперь перейдём к <body>. В нём находятся 2 элемента <h2> и <ul>, и так далее.
При этом, как вы уже поняли, узлы в зависимости от того, чем они образованы делятся на разные типы. В DOM выделяют:
В DOM выделяют:
- узел, представляющий собой весь документ; этим узлом является объект
document; он выступает входной точкой в DOM; - узлы, образованные тегами, их называют узлами-элементами или просто элементами;
- текстовые узлы, они образуются текстом внутри элементов;
- узлы-комментарии и так далее.
Имеются и другие типы узлов, но на практике в основном используются только перечисленные выше.
Каждый узел в дереве DOM является объектом. Но при этом формируют структуру DOM только узлы-элементы. Текстовые узлы, например, содержат в себе только текст. Они не могут содержать внутри себя другие узлы. Поэтому вся работа с DOM в основном связана с узлами-элементами.
Кстати, директива <!doctype html> тоже является DOM-узлом. Но она нам не интересна, поэтому на схеме мы её опустили.
Чтобы перемещаться по узлам DOM-дерева нужно знать какие они имеют отношения. Зная их можно будет выбирать правильные свойства и методы. Связи между узлами, определяются их вложенностью. Каждый узел в DOM может иметь следующие виды отношений:
Связи между узлами, определяются их вложенностью. Каждый узел в DOM может иметь следующие виды отношений:
- родитель – это узел, в котором он непосредственно расположен; при этом родитель у узла может быть только один; также узел может не иметь родителя, в данном примере им является
document; - дети или дочерние узлы – это все узлы, которые расположены непосредственно в нём; например, узел
<ul>имеет 2 детей; - соседи или сиблинги – это узлы, которые имеют такого же родителя что и этот узел;
- предки – это его родитель, родитель его родителя и так далее;
- потомки – это все узлы, которые расположены в нем, то есть это его дети, а также дети его детей и так далее.
Например, узел-элемент <h2> имеет в качестве родителя <body>. Ребенок у него один – это текстовый узел «Мобильные ОС». Сосед у него тоже только один – это <ul>.
Теперь рассмотрим, каких предков имеет текстовый узел «iOS». У него они следующие: <li>, <ul>, <body> и <html>.
У элемента <head> 2 потомка: <title> и текстовый узел «Моя страница».
Зачем нужно знать, как строится DOM-дерево? Во-первых, это понимание той среды, в которой вы хотите что-то изменять. Во-вторых, большинство действий при работе с DOM сводится к поиску нужных элементов. Но не зная как устроено DOM-дерево и отношения между узлами, найти что-то в нём будет достаточно затруднительно.
Задания
1. Представленное DOM-дерево преобразуйте обратно в HTML-код:
Следующая тема: Узлы DOM-дерева.
Что такое объектная модель документа?
Что такое объектная модель документа?
- Редакторы
- Джонатан Роби, Texcel Research
Введение
Объектная модель документа (DOM) — это программный API для HTML и
XML-документы. Он определяет логическую структуру документов и
Он определяет логическую структуру документов и
способ доступа к документу и манипулирования им. В спецификации DOM
термин «документ» используется в широком смысле — XML все чаще используется в качестве
способ представления различных видов информации, которые могут
храниться в различных системах, и большая часть этого традиционно
рассматриваться как данные, а не как документы. Тем не менее, XML представляет
эти данные как документы, и DOM может использоваться для управления этими данными.
С документом
Объектная модель, программисты могут создавать и создавать документы, перемещаться
их структуру, а также добавлять, изменять или удалять элементы и содержимое.
Можно получить доступ ко всему, что находится в документе HTML или XML,
изменены, удалены или добавлены с помощью объектной модели документа,
за некоторыми исключениями — в частности, DOM-интерфейсы для
внутреннее подмножество и внешнее подмножество еще не определены.
В спецификации W3C одной из важных целей документа
Объектная модель должна предоставлять стандартный программный интерфейс, который
могут использоваться в самых разных средах и приложениях.
Объектную модель документа можно использовать с любым программным обеспечением.
язык. Чтобы обеспечить точную, независимую от языка спецификацию
интерфейсов объектной модели документа мы решили определить
спецификации в OMG IDL, как определено в CORBA 2.2
Спецификация.
В дополнение к спецификации OMG IDL,
мы предоставляем языковые привязки для Java и ECMAScript (
стандартный отраслевой язык сценариев на основе JavaScript и
JScript). Примечание. OMG IDL используется только как независимая от языка и
независимый от реализации способ указания интерфейсов. Различные другие
Можно было бы использовать IDL; использование OMG IDL не подразумевает
требование использовать конкретную среду выполнения привязки объекта.
Что такое объектная модель документа
Объектная модель документа — это программный API для документов.
Сама объектная модель очень похожа на структуру
документирует его модели. Например, рассмотрим эту таблицу, взятую
из документа HTML:
<ТАБЛИЦА>
<СТРОКИ>
Тенистая роща
Эолийский
За рекой, Чарли
Дориан
Объектная модель документа представляет эту таблицу следующим образом:
DOM-представление примера таблицы
В объектной модели документа документы имеют логический
структура, очень похожая на дерево; если быть точнее, то
подобен «лесу» или «роще», которые могут
содержать более одного дерева. Однако объектная модель документа
не указывает, что документы должны быть реализованы как
дерево или роща, ни
указывает ли он, как должны быть связаны отношения между объектами?
реализованы в любом случае. Другими словами, объектная модель
Другими словами, объектная модель
определяет логическую модель для интерфейса программирования и
эта логическая модель может быть реализована любым способом, который
конкретная реализация находит удобной. В этом
спецификации, мы используем термин модель конструкции до
описать древовидное представление документа; мы
специально избегайте таких терминов, как «дерево» или
«роща», чтобы не подразумевать конкретное
выполнение. Одно важное свойство моделей структуры DOM
является структурным изоморфизмом : если любые два документа
Реализации объектной модели используются для создания представления
одного и того же документа они создадут одну и ту же модель структуры,
с точно такими же объектами и отношениями.
Название «Объектная модель документа» было выбрано потому, что
это «объектная модель», используемая в традиционном
смысл объектно-ориентированного дизайна: документы моделируются с использованием
объекты, и модель охватывает не только структуру
документ, но и поведение документа и объектов
из которых он состоит. Другими словами, узлы в
Другими словами, узлы в
приведенная выше диаграмма не представляет структуру данных, они
представляют объекты, которые имеют функции и идентичность. Как
объектная модель, объектная модель документа идентифицирует:
- интерфейсы и объекты, используемые для представления и управления
документ - семантика этих интерфейсов и объектов, в том числе
как поведение, так и атрибуты - отношения и сотрудничество между этими интерфейсами
и объекты
Структура документов SGML традиционно
представлена абстрактной моделью данных, а не объектной моделью.
В абстрактной модели данных модель сосредоточена вокруг
данные. В объектно-ориентированных языках программирования сами данные
инкапсулируется в объекты, которые скрывают данные, защищая их
от прямых внешних манипуляций. Функции, связанные с
эти объекты определяют, как с ними можно манипулировать, и
они являются частью объектной модели.
Объектная модель документа в настоящее время состоит из двух частей:
DOM Core и DOM HTML. Ядро DOM представляет собой
Ядро DOM представляет собой
функциональность, используемая для XML-документов, а также служит
основа для DOM HTML. Все реализации DOM должны поддерживать
интерфейсы, указанные как «фундаментальные» в спецификации Core;
кроме того, реализации XML должны поддерживать интерфейсы
указан как «расширенный» в спецификации Core. Уровень 1
Спецификация DOM HTML определяет дополнительную функциональность
требуется для HTML-документов.
Чем не является объектная модель документа
Этот раздел предназначен для более точного понимания
объектной модели документа, отличая ее от других
системы, которые могут показаться похожими на это.
- Хотя объектная модель документа находилась под сильным влиянием
динамическим HTML, на уровне 1 он не реализует все
Динамический HTML. В частности, события еще не определены.
Уровень 1 предназначен для того, чтобы заложить прочную основу для такого рода
функциональности, предоставляя надежную и гибкую модель
сам документ. - Объектная модель документа не является двоичной спецификацией. Документ
Программы объектной модели, написанные на одном языке, будут
исходный код совместим на разных платформах, но Document
Объектная модель не определяет какую-либо форму двоичного
совместимость. - Объектная модель документа не является способом сохранения объектов
в XML или HTML. Вместо указания того, как объекты могут быть
представленная в XML, объектная модель документа определяет, как
Документы XML и HTML представлены в виде объектов, поэтому
они могут использоваться в объектно-ориентированных программах. - Объектная модель документа не является набором структур данных,
это объектная модель, определяющая интерфейсы. Хотя это
документ содержит диаграммы, показывающие отношения родитель/потомок,
это логические отношения, определенные программой
интерфейсы, а не представления каких-либо конкретных внутренних
структуры данных. - Объектная модель документа не определяет «истинный
внутренняя семантика» XML или HTML. Семантика этих
языки определяются самими языками.
Объектная модель документа — это модель программирования, предназначенная для
уважайте эту семантику. Объектная модель документа не
иметь какие-либо последствия для того, как вы пишете XML и HTML
документы; любой документ, который может быть написан на этих языках
могут быть представлены в объектной модели документа. - Объектная модель документа, несмотря на свое название, не является
конкурент объектной модели компонентов (COM). COM, как
CORBA — это независимый от языка способ указания интерфейсов и
объекты; Объектная модель документа представляет собой набор интерфейсов и
объекты, предназначенные для управления документами HTML и XML. Дом
может быть реализован с использованием независимых от языка систем, таких как COM
или КОРБА; это также может быть реализовано с использованием специфичных для языка
привязки, такие как привязки Java или ECMAScript, указанные в
этот документ.

 Семантика этих
Семантика этихОткуда взялась объектная модель документа
Объектная модель документа возникла как спецификация для
позволить сценариям JavaScript и программам Java быть переносимыми между
веб-браузеры.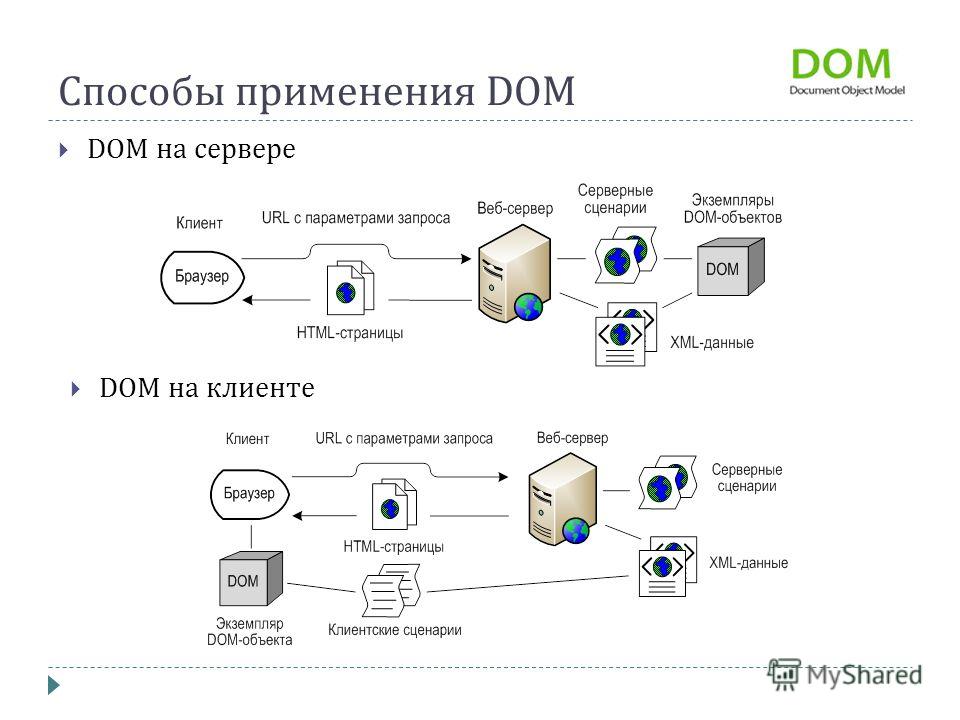 Динамический HTML был непосредственным предком
Динамический HTML был непосредственным предком
Документировать объектную модель, и изначально предполагалось, что
с точки зрения браузеров. Однако, когда объектная модель документа
Была сформирована рабочая группа, к ней также присоединились вендоры в других
домены, включая редакторы HTML или XML и документы
репозитории. Некоторые из этих поставщиков работали с SGML.
до того, как был разработан XML; в результате объектная модель документа
находился под влиянием SGML Groves и стандарта HyTime. Некоторый
из этих поставщиков также разработали свои собственные объектные модели для
документы для предоставления программных API для SGML/XML
редакторы или репозитории документов, и эти объектные модели имеют
также повлияла на объектную модель документа.
Сущности и DOM Core
В основных интерфейсах DOM нет объектов, представляющих
сущности. Ссылки на числовые символы и ссылки на
предварительно определенные объекты в HTML и XML заменяются
одиночный символ, который составляет замену сущности.
Например, в:
Это собака & кошка
«&»
будет заменен символом «&», а
текст в элементе
будет формировать единый непрерывный
последовательность символов. Представительство генерала
объекты, как внутренние, так и внешние, определяются в
расширенные (XML) интерфейсы спецификации уровня 1.
Примечание. Когда DOM-представление документа сериализуется
как текст XML или HTML, приложения должны будут проверять каждый
символ в текстовых данных, чтобы увидеть, нужно ли его экранировать
с использованием числового или предварительно определенного объекта. Не сделать этого
может привести к недопустимому HTML или XML.
Интерфейсы DOM и реализации DOM
DOM определяет интерфейсы, которые могут использоваться для управления XML или
HTML-документы. Важно понимать, что эти интерфейсы
являются абстракцией — так же, как «абстрактные базовые классы» в C++,
они являются средством определения способа доступа и манипулирования
внутреннее представление документа приложением. В
В
частности, интерфейсы не подразумевают конкретного конкретного
выполнение. Каждое приложение DOM может поддерживаться бесплатно.
документы в любом удобном представлении, лишь бы
интерфейсы, показанные в этой спецификации, поддерживаются. Некоторый
Реализациями DOM будут существующие программы, использующие
Интерфейсы DOM для доступа к программному обеспечению, написанному задолго до
Спецификация DOM существовала. Таким образом, DOM разработан
чтобы избежать зависимостей реализации; в частности,
- Атрибуты, определенные в IDL, не предполагают конкретного
объекты, которые должны иметь определенные элементы данных — в
языковые привязки, они переводятся в пару
get()/set(), а не члену данных. (только для чтения
функции имеют только функцию get() в языке
привязки). - Приложения DOM могут предоставлять дополнительные интерфейсы
и объекты, не найденные в этой спецификации, и по-прежнему будут
считается совместимым с DOM. - Поскольку мы указываем интерфейсы, а не фактические
объекты, которые должны быть созданы, DOM не может знать, что
конструкторы для вызова реализации. В общем,
Пользователи DOM вызывают методы createXXX() в документе.
класс для создания структур документов и DOM
реализации создают свои собственные внутренние представления
этих структур в их реализациях
функции createXXX().
 В общем,
В общем,Ограничения первого уровня
Спецификация DOM уровня 1 намеренно ограничена
те методы, которые необходимы для представления и управления документом
структура и содержание.
Будущие уровни спецификации DOM обеспечат:
- Структурная модель для внутреннего подмножества и
внешнее подмножество. - Проверка по схеме.
- Управление рендерингом документов через таблицы стилей.
- Контроль доступа.
- Защита от потоков.
Что такое объектная модель документа?
Что такое объектная модель документа?
REC-DOM-Level-1-19981001
- Редакторы
- Джонатан Роби, Texcel Research
Введение
Объектная модель документа (DOM) — это интерфейс прикладного программирования (API) для HTML и
XML-документы. Он определяет логическую структуру документов и
Он определяет логическую структуру документов и
способ доступа к документу и манипулирования им. В спецификации DOM
термин «документ» используется в широком смысле — XML все чаще используется в качестве
способ представления различных видов информации, которые могут
храниться в различных системах, и большая часть этого традиционно
рассматриваться как данные, а не как документы. Тем не менее, XML представляет
эти данные как документы, и DOM может использоваться для управления этими данными.
С документом
Объектная модель, программисты могут создавать документы, перемещаться
их структуру, а также добавлять, изменять или удалять элементы и содержимое.
Можно получить доступ ко всему, что находится в документе HTML или XML,
изменены, удалены или добавлены с помощью объектной модели документа,
за некоторыми исключениями — в частности, DOM-интерфейсы для
внутренние и внешние подмножества XML еще не определены.
В спецификации W3C одной из важных целей документа
Объектная модель должна предоставлять стандартный программный интерфейс, который
могут использоваться в самых разных средах и приложениях.
DOM предназначен для использования с любым программированием.
язык. Чтобы предоставить точную, независимую от языка спецификацию
интерфейсов DOM мы решили определить
спецификации в OMG IDL, как определено в CORBA 2.2
Спецификация.
В дополнение к спецификации OMG IDL,
мы предоставляем языковые привязки для Java и ECMAScript (
стандартный отраслевой язык сценариев на основе JavaScript и
JScript). Примечание. OMG IDL используется только как независимая от языка и
независимый от реализации способ указания интерфейсов. Различные другие
Можно было бы использовать IDL. Как правило, IDL предназначены для
конкретные вычислительные среды. Объектная модель документа
может быть реализован в любой вычислительной среде и не
требуется среда выполнения привязки объекта, обычно связанная с
такие ИДЛ.
Что такое объектная модель документа
DOM — это программный API для документов.
Он очень похож на структуру
документирует его модели. Например, рассмотрим эту таблицу, взятую
Например, рассмотрим эту таблицу, взятую
из документа HTML:
<ТАБЛИЦА>
Тенистая роща
Эолийский
За рекой, Чарли
Дориан
DOM представляет эту таблицу следующим образом:
DOM-представление примера таблицы
В DOM документы имеют логическую
структура, очень похожая на дерево; если быть точнее, то
подобен «лесу» или «роще», которые могут
содержать более одного дерева. Тем не менее, ДОМ.
не указывает, что документы должны быть реализованы как
дерево или роща, ни
указывает ли он, как должны быть связаны отношения между объектами?
реализовано. DOM — это логическая модель, которая может быть реализована в любой
удобный способ. В этом
спецификации, мы используем термин модель конструкции до
описать древовидное представление документа; мы
специально избегайте таких терминов, как «дерево» или
«роща», чтобы не подразумевать конкретное
выполнение. Одно важное свойство моделей структуры DOM
Одно важное свойство моделей структуры DOM
является структурным изоморфизмом : если любые два документа
Реализации объектной модели используются для создания представления
одного и того же документа они создадут одну и ту же модель структуры,
с точно такими же объектами и отношениями.
Название «Объектная модель документа» было выбрано потому, что
это «объектная модель» в традиционном
смысл объектно-ориентированного дизайна: документы моделируются с использованием
объекты, и модель охватывает не только структуру
документ, но и поведение документа и объектов
из которых он состоит. Другими словами, узлы в
приведенная выше диаграмма не представляет структуру данных, они
представляют объекты, которые имеют функции и идентичность. Как
объектная модель, DOM идентифицирует:
- интерфейсы и объекты, используемые для представления и управления
документ - семантика этих интерфейсов и объектов, в том числе
как поведение, так и атрибуты - отношения и сотрудничество между этими интерфейсами
и объекты
Структура документов SGML традиционно
представлена абстрактной моделью данных, а не объектной моделью.
В абстрактной модели данных модель сосредоточена вокруг
данные. В объектно-ориентированных языках программирования сами данные
инкапсулируется в объекты, которые скрывают данные, защищая их
от прямых внешних манипуляций. Функции, связанные с
эти объекты определяют, как с ними можно манипулировать, и
они являются частью объектной модели.
Объектная модель документа в настоящее время состоит из двух частей:
DOM Core и DOM HTML. Ядро DOM представляет собой
функциональность, используемая для XML-документов, а также служит
основа для DOM HTML.
Соответствующая реализация DOM должна реализовывать все
фундаментальные интерфейсы в главе Core с семантикой как
определенный. Кроме того, он должен реализовать по крайней мере одну из HTML DOM.
и расширенные (XML) интерфейсы с определенной семантикой.
Чем не является объектная модель документа
Этот раздел предназначен для более точного понимания
DOM, отличая его от других
системы, которые могут показаться похожими на это.
- Хотя объектная модель документа находилась под сильным влиянием
«Динамический HTML» на уровне 1 не реализует все
«Динамический HTML». В частности, события еще не определены.
Уровень 1 предназначен для того, чтобы заложить прочную основу для такого рода
функциональности, предоставляя надежную и гибкую модель
сам документ. - Объектная модель документа не является двоичной спецификацией.
DOM-программы, написанные на одном языке, будут
исходный код совместим на разных платформах, но DOM
не определяет какую-либо форму бинарного взаимодействия. - Объектная модель документа не является способом сохранения объектов
в XML или HTML. Вместо указания того, как объекты могут быть
представленный в XML, DOM указывает, как
Документы XML и HTML представлены в виде объектов, поэтому
они могут использоваться в объектно-ориентированных программах. - Объектная модель документа не является набором структур данных,
это объектная модель, определяющая интерфейсы. Хотя это
документ содержит диаграммы, показывающие отношения родитель/потомок,
это логические отношения, определенные программой
интерфейсы, а не представления каких-либо конкретных внутренних
структуры данных. - Объектная модель документа не определяет «истинный
внутренняя семантика» XML или HTML. Семантика этих
языки определяются Рекомендациями W3C для этих языков.
DOM — это модель программирования, предназначенная для
уважайте эту семантику. DOM не
иметь какие-либо последствия для того, как вы пишете XML и HTML
документы; любой документ, который может быть написан на этих языках
могут быть представлены в DOM. - Объектная модель документа, несмотря на свое название, не является
конкурент объектной модели компонентов (COM). COM, как
CORBA — это независимый от языка способ указания интерфейсов и
объекты; DOM представляет собой набор интерфейсов и
объекты, предназначенные для управления документами HTML и XML. Дом
может быть реализован с использованием независимых от языка систем, таких как COM
или КОРБА; это также может быть реализовано с использованием специфичных для языка
привязки, такие как привязки Java или ECMAScript, указанные в
этот документ.

Откуда взялась объектная модель документа
Модель DOM возникла как спецификация для
позволить сценариям JavaScript и программам Java быть переносимыми между
Веб-браузеры. «Динамический HTML» был непосредственным предком
«Динамический HTML» был непосредственным предком
Документировать объектную модель, и изначально предполагалось, что
с точки зрения браузеров. Однако, когда ДОМ
Рабочая группа была сформирована в W3C, к ней также присоединились вендоры из других
домены, включая редакторы HTML или XML и документы
репозитории. Некоторые из этих поставщиков работали с SGML.
до того, как был разработан XML; в результате ДОМ
находился под влиянием SGML Groves и стандарта HyTime. Некоторый
из этих поставщиков также разработали свои собственные объектные модели для
документов для предоставления API для SGML/XML
редакторы или репозитории документов, и эти объектные модели имеют
также повлияли на DOM.
Сущности и DOM Core
В основных интерфейсах DOM нет объектов, представляющих
сущности. Ссылки на числовые символы и ссылки на
предварительно определенные объекты в HTML и XML заменяются
одиночный символ, который составляет замену сущности.
Например, в:
Это собака & кот
«&» будет заменен символом «&», а текст
в элементе P будут образовывать единую непрерывную последовательность
персонажи. Поскольку числовые ссылки на символы и предварительно определенные объекты
не распознаются как таковые в разделах CDATA или в SCRIPT и STYLE
элементы в HTML, они не заменяются одним символом, который они
кажется, ссылаются на. Если бы приведенный выше пример был заключен в CDATA
раздел «&» не будет заменен на «&»; ни один не будет
распознается как начальный тег. Представительство генерала
объекты, как внутренние, так и внешние, определяются в
расширенные (XML) интерфейсы спецификации уровня 1.
Примечание. Когда DOM-представление документа сериализуется
как текст XML или HTML, приложения должны будут проверять каждый
символ в текстовых данных, чтобы увидеть, нужно ли его экранировать
с использованием числового или предварительно определенного объекта. Не сделать этого
Не сделать этого
может привести к недопустимому HTML или XML. Кроме того, реализации должны быть
известно о том, что сериализация в кодировку символов
(«набор символов»), который не полностью охватывает ISO 10646, может дать сбой, если есть
символы в разделах разметки или CDATA, которых нет в
кодирование.
Интерфейсы DOM и реализации DOM
DOM определяет интерфейсы, которые могут использоваться для управления XML или
HTML-документы. Важно понимать, что эти интерфейсы
являются абстракцией — так же, как «абстрактные базовые классы» в C++,
они являются средством определения способа доступа и манипулирования
внутреннее представление документа приложением. Интерфейсы
не подразумевает конкретного конкретного
выполнение. Каждое приложение DOM может поддерживаться бесплатно.
документы в любом удобном представлении, лишь бы
интерфейсы, показанные в этой спецификации, поддерживаются. Некоторый
Реализациями DOM будут существующие программы, использующие
Интерфейсы DOM для доступа к программному обеспечению, написанному задолго до
Спецификация DOM существовала. Таким образом, DOM разработан
Таким образом, DOM разработан
чтобы избежать зависимостей реализации; в частности,
- Атрибуты, определенные в IDL, не предполагают конкретного
объекты, которые должны иметь определенные элементы данных — в
языковые привязки, они переводятся в пару
get()/set(), а не члену данных. (только для чтения
функции имеют только функцию get() в языке
привязки). - Приложения DOM могут предоставлять дополнительные интерфейсы
и объекты, не найденные в этой спецификации, и по-прежнему будут
считается совместимым с DOM. - Поскольку мы указываем интерфейсы, а не фактические
объекты, которые должны быть созданы, DOM не может знать, что
конструкторы для вызова реализации. В общем,
Пользователи DOM вызывают методы createXXX() в документе.
класс для создания структур документов и DOM
реализации создают свои собственные внутренние представления
этих структур в их реализациях
функции createXXX().
Ограничения уровня 1
Спецификация DOM уровня 1 намеренно ограничена
те методы, которые необходимы для представления и управления документом
структура и содержание.